
业界专家一致认为,常规的端到端方案最终只能实现L3级自动驾驶,生成式AI大模型才能实现L4。
那么,大模型技术真正在车端落地,需要突破多少难关呢?
01
对大佬们的话做阅读理解,一定要结合他发言的上下文,否则很容易断章取义。
比方说,特斯拉前自动驾驶部门负责人Andrej Karpathy曾经说过,大模型的幻觉是特点,不是缺陷,大语言模型的工作机制就是做梦,幻觉是正常现象。
从助力科学发现的角度来看,大模型的幻觉问题的确不是缺陷。
但是,对于汽车驾驶这种高安全要求、约束边界非常明显的场景而言,幻觉问题是必须解决的一道难关。

定量来看,当下大模型的错误率和L4级自动驾驶能容忍的错误率到底有多大的差距呢?
华为在《云计算2030》中表示,L3级自动驾驶的容错率为0.1-1%,L4级自动驾驶容错率在0.0001-0.001%之间。

随着参数量的加大、训练数据规模的提升和新方法的引入,大模型的准确率一直在稳步提升。
2020年问世的GPT3错误率在40%左右,到了2022年底,GPT3.5的错误率已经下降到了20%,GPT4更是百尺竿头、更进一步,将错误率降低到了10%。
不过,饶是如此,10%和L4级自动驾驶的容错率0.0001%依然差着5个数量级。

前段时间,理想汽车的双系统方案在直播测试中公然逆行,暴露了由LLM改造而来的视觉语言模型输出错误率依然不低的现实。
理想的视觉语言模型DriveVLM基于阿里巴巴的Qwen-VL或Meta的LLaMA2-3B改造而来。
即便在它们的基础上新增训练了一些驾驶场景数据,做了RAG检索增强、AI对齐、强化学习、优化提示词等工作,准确率的提升也相当有限。

幻觉问题的解决任重而道远。
前段时间,李彦宏在百度世界2024大会上表示:过去两年AI行业的最大变化就是大模型基本消除了幻觉。
我们无从揣测李彦宏是不是出现了幻觉,但他这个观点非常值得商榷。
在绝大多数情况下,文字只不过是无关痛痒的表达,操纵钢铁巨兽的自动驾驶系统面对的却是可以直接决定他人性命,务必要慎之再慎!
02
有人说,人生最大的幸福就是在对的时间和环境下,和对的人一起做对的事,一旦时间变了,一切就都变了。
自动驾驶也要在对的时间、空间下,及时地做出对的决策,实时地行驶出对的轨迹。
交通场景瞬息万变,自动驾驶系统必须及时感知车辆周围环境、实时预判周围交通参与者的潜在轨迹,经过整体的统筹,即时规划出安全、舒适、高效的行驶路径。

要保证复杂车流环境下的实时性,模型的运行频率至少要在十几赫兹。
目前,理想汽车视觉语言模型的运行频率在3.3赫兹左右,只能起到辅助提醒的作用,无法参与实时的轨迹规划。
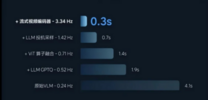
现在坊间有一个简单粗暴的观点,理想汽车如果在下一代智驾系统中将Orin升级为英伟达下一代舱驾一体芯片Thor。
NPU从254 TOPS提升到1000 TOPS。再加上Thor对Transformer架构的原生支持,应该有望将DriveVLM的运行频率提高到十几赫兹。

这个看法相当门外汉。天上云追月,地下风吹柳,更高等级的自动驾驶对模型的参数量必然有着更高的需求。
目前,理想汽车用来实现L3级自动驾驶的视觉语言模型的参数量只有22亿参数,这种参数规模的大模型无法实现L4级自动驾驶。

可以拿特斯拉FSD的模型参数量做个对比。
2022年的AI Day上,特斯拉披露了其分模块方案FSD的参数规模为10亿(1B),进化到端到端方案之后,FSD模型的参数量必然有增无减。
特斯拉曾经表示过,从V12.4到V12.5,FSD模型参数量提高了5倍,从V12.5到志在实现L4级自动驾驶的V13,模型参数量再次提高了3倍。
做一个合理的推算,FSD当前的模型参数量恐怕得在200亿左右,比DriveVLM的22亿参数量高了整整1个数量级。
这就意味着,除非降低对自动驾驶能力等级的需求,即将量产的智能驾驶芯片标杆英伟达雷神芯片也无法解决车端运行大模型的实时性难题。
03
万丈高楼平地起,那是因为有地基。
进入2024年下半年,本土智驾企业纷纷开启在车端自动驾驶大模型上的实践,并非因为他们自己水平有多么强悍,而是因为头部AI企业训练出并开源了具备图像理解能力的多模态大模型。
智驾企业们在这些涵盖多个不同科目和子领域、具备通用多模态能力的视觉模型/视觉语言模型/视觉语言动作模型的基础上,再设计一些面向驾驶场景的问答,进行简单的微调训练,自家的视觉语言智驾大模型就顺利出炉了。

这些万亿美金市值的AI巨头提供了免费的午餐,也顺带着决定了基于它们改造而来的智驾视觉语言模型的性能天花板。
先说乐观的一面,这些大模型具备图文识别能力,可用于识别潮汐车道、公交车道、路牌文字,理想汽车的VLM可以结合当前时间段给出使用或驶离公交车道的建议,其能力就来自这里。

这些大模型也具备一定的场景理解能力,比如判断路面的坑洼情况,给出减速建议。
当然,如果自家的车型具备真正的魔毯能力,或许只需要适时调节空悬和CDC就可以了。

再说悲观的一面,这些面向数字世界的AI大模型并不具备真正的空间理解能力。
建立空间理解能力的关键在于可以同时输入车前、车后、左前、右前、左后、右后的多个摄像头的图像输入,站在3D视角下进行综合的判断,BEV前融合的价值就在这里。
反观视觉语言模型,虽然可以依次输入前视、后视、周视摄像头采集到的图像,但它只能像BEV出现之前的自动驾驶算法那样做后融合,直接杜绝了建立精准的空间理解能力的可能。
目前的智驾视觉语言模型只能给出车道、加减速这些中间层的建议,而无法输出最终的轨迹,本质原因就在这里,特斯拉和蔚来汽车死磕具备空间理解能力的世界模型的本质原因也在这里。
生成式AI爆发之后,业界对自动驾驶能力的进展速度一度变得非常乐观,但是,从以上分析可以看出,通过生成式AI大模型提升自动驾驶能力,这条路依然任重道远!








 蜀ICP备2021015352号-6
蜀ICP备2021015352号-6